CIS 1051 - Temple Rome Spring 2024¶
![]()
Lists¶
Prof. Dario Abbondanza
A List Is a Sequence¶
lists are sequences of values (like strings).
- In a string, the values are characters.
- In a list, they can be any type.
The values in a list are called elements or sometimes items.
To enclose elements in square brackets [ and ] is the simplest way to create a new list (among several others)
[10, 20, 30, 40]
['crunchy frog', 'ram bladder', 'lark vomit']
- first example is a list of four integers.
- second example is a list of three strings.
The elements of a list don’t have to be the same type:
['spam', 2.0, 5, [10, 20]]
A list within another list is nested.
A list with no elements is an empty list.
Create one with empty brackets:
[]
We can assign list values to variables:
cheeses = ['Cheddar', 'Edam', 'Gouda']
numbers = [42, 123]
empty = []
print(cheeses, numbers, empty)
['Cheddar', 'Edam', 'Gouda'] [42, 123] []
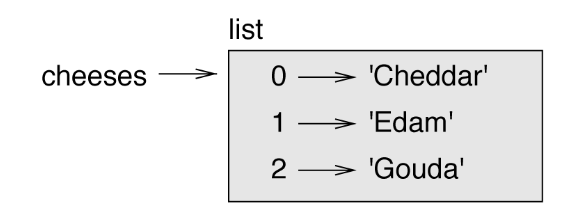
cheeses refers to a list with three elements indexed 0, 1 and 2.
![]()
empty refers to a list with no elements.
Lists Are Mutable¶
For accessing list elements (bracket operator) same syntax as for accessing string characters.
- Expressions inside brackets specify the index.
- Indices start at
0. - Any integer expression can be used as an index.
cheeses[0]
'Cheddar'
Unlike strings, lists are mutable.
The bracket operator on the left side (of an assignment) identifies the element to be assigned.
numbers[1] = 5
numbers
[42, 5]
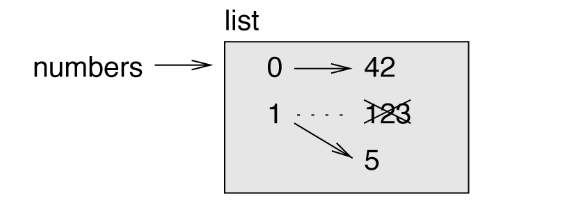
The one-eth element of numbers, which used to be 123, is now 5.
List indices work the same way as string indices:
- If you try to read or write an element that does not exist, you get an
IndexError. - If an index has a negative value, it counts backward from the end of the list.
The in operator works on lists too:
'Edam' in cheeses
True
'Brie' in cheeses
False
Traversing a List¶
The most common way is with a for loop (same as for strings):
for cheese in cheeses:
print(cheese)
Cheddar Edam Gouda
... but to write/update its elements, we need the indices:
for i in range(len(numbers)):
numbers[i] = numbers[i] * 2
numbers
[84, 10]
Combining built-in functions range and len:
lenreturns the number of elements in the list.rangereturns a list of indices up to the list the length.ito read the old value / to assign the new value.
A for loop over an empty list never runs the body:
for x in []:
print('This never happens.')
Although a list can contain another list, the nested list still counts as a single element.
len(['spam', 1, ['Brie', 'Roquefort', 'Pol le Veq'], [1, 2, 3]])
4
The length of this list is four.
List Operations¶
The + operator concatenates lists:
a = [1, 2, 3]
b = [4, 5, 6]
c = a + b
c
[1, 2, 3, 4, 5, 6]
The * operator repeats a list a given number of times:
[0] * 4
[0, 0, 0, 0]
[1, 2, 3] * 3
[1, 2, 3, 1, 2, 3, 1, 2, 3]
List Slices¶
The slice operator : works on lists the same way as for strings
t = ['a', 'b', 'c', 'd', 'e', 'f']
t[1:3]
['b', 'c']
t[:4]
['a', 'b', 'c', 'd']
omitting the first index, the slice starts at the beginning
t[3:]
['d', 'e', 'f']
omitting the second index, the slice goes to the end
t[:]
['a', 'b', 'c', 'd', 'e', 'f']
omitting both indices, the slice is a copy of the whole list
Being mutable, it's useful to make a copy before modifying them.
t[1:3] = ['x', 'y']
t
['a', 'x', 'y', 'd', 'e', 'f']
slice operator on the left side updates multiple elements.
List Methods¶
Python provides methods that operate on lists.
t1 = ['a', 'b', 'c']
t1.append('d')
t1
['a', 'b', 'c', 'd']
append adds a new element to the end of a list.
t2 = ['d', 'e']
t1.extend(t2)
t1
['a', 'b', 'c', 'd', 'd', 'e']
extend appends all of the elements of a list passed as argument.
... leaving the second list t2 unmodified.
t3 = ['d', 'c', 'e', 'b', 'a']
t3.sort()
t3
['a', 'b', 'c', 'd', 'e']
sort arranges the list elements from low to high.
Most list methods are void; they modify the list and return None.
Map, Filter and Reduce¶
To add up all the numbers in a list, we could use a loop like this:
def add_all(t):
total = 0
for x in t:
total += x
return total
totalis initialized to0.totalaccumulates the sum of the elements.
A variable used this way is an accumulator.
The += operator (aka augmented assignment statement) provides a short way to update a variable.
total += x
is equivalent to
total = total + x
Python provides a built-in function for adding up the elements of a list:
t = [1, 2, 3]
sum(t)
6
Operations like this (combining elements into a single value) are called reduce.
We may want to traverse one list while building another: taking a list of strings and returning a new one, with capitalized strings:
def capitalize_all(t):
res = []
for s in t:
res.append(s.capitalize())
return res
here res is another kind of accumulator.
An operation like this is a map because it “maps” a function onto each of the elements in a sequence.
Otherwise, if we want to select some elements and return a sublist: taking a list of strings and returning uppercase strings only:
def only_upper(t):
res = []
for s in t:
if s.isupper():
res.append(s)
return res
isupper is a string method that returns True if the string contains only uppercase letters.
Operations like this are a filter, selecting some elements only and filtering out the others.
Most common list operations can be expressed as a combination of map, filter and reduce.
Deleting Elements¶
There are several ways to delete list elements.
Knowing the element index we can use pop:
t = ['a', 'b', 'c']
x = t.pop(1)
t
['a', 'c']
it modifies the list and returns the element that was removed.
x
'b'
Providing no index, the last element is affected (removed/returned).
Don’t need the removed value? Use the del operator:
t = ['a', 'b', 'c']
del t[1]
t
['a', 'c']
Don't know the element index to remove? Use remove:
t = ['a', 'b', 'c', 'd', 'e', 'f']
del t[1:5]
t
['a', 'f']
Lists and Strings¶
A string is a sequence of characters.
A list is a sequence of values, but a list of characters is not the same as a string.
To convert string to a list of characters, use list:
s = 'spam'
t = list(s)
t
['s', 'p', 'a', 'm']
It breaks a string into individual letters.
Avoid using list as a variable name, being the name of a built-in function.
To break a string into words, let's use the split method:
s = 'pining for the fjords'
t = s.split()
t
['pining', 'for', 'the', 'fjords']
passing a delimiter as optional argument to specify the characters to use as word boundaries.
s = 'spam-spam-spam'
delimiter = '-'
t = s.split(delimiter)
t
['spam', 'spam', 'spam']
join is the inverse of split, taking a list of strings to concatenate them.
t = ['pining', 'for', 'the', 'fjords']
delimiter = ' '
s = delimiter.join(t)
s
'pining for the fjords'
It is a string method: invoke it on the delimiter and pass the list as a parameter.
Here the delimiter was a space character ' '.
To concatenate strings without spaces, simply use the empty string '' as a delimiter.
Objects and Values¶
Running these assignment statements:
a = 'banana'
b = 'banana'
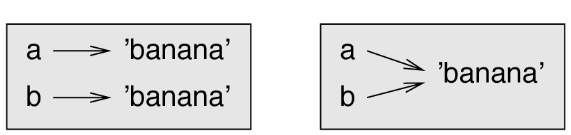
Both `a` and `b` refer to a string, but do they refer to the same string ?
- Do they refer to two different objects that have the same value?
- Do they refer to the same object?
Let's check using the is operator:
a is b
True
Here Python creates just one string object, making both variables refer to it.
Contrary, creating two lists, we get two objects:
a = [1, 2, 3]
b = [1, 2, 3]
a is b
False

We used so far “object” and “value” interchangeably, but it is more correct to say: an object has a value.
Two objects are indentical when they are the same object; they are equivalent when they have the same value.
Aliasing¶
assigning b = a (when a refers to an object), both variables refer to the same object.
a = [1, 2, 3]
b = a
b is a
True

Associating a variable with an object is a reference.
An object with more than one reference has more than one name (aka aliased).
If the aliased object is mutable, changes made with one alias affect the other:
b[0] = 42
a
[42, 2, 3]
This behavior can be useful, but it's error-prone.
Safer to avoid aliasing working with mutable objects.
For immutable objects like strings, aliasing is not as much of a problem.
It almost never makes a difference.
List Arguments¶
def delete_head(t):
del t[0]
passing a list to a function, it gets a reference to the list.
If the function modifies the list, the caller sees the change. This function removes the first element from a list:
letters = ['a', 'b', 'c']
delete_head(letters)
letters
['b', 'c']
The parameter t and the variable letters are aliases for the same object: the list is shared by two frames.
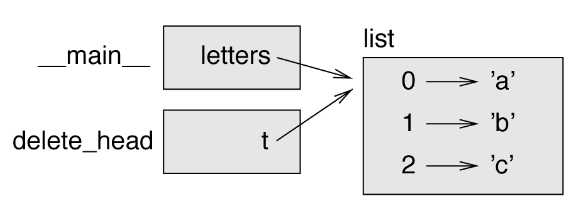
Distinguish between:
- operations that modify lists
- operations that create new lists
t1 = [1, 2]
t2 = t1.append(3)
t1
[1, 2, 3]
the append method modifies a list and returns None
t2 is None
True
The + operator creates a new list,
t3 = t1 + [4]
t1
[1, 2, 3]
leaving the original one unchanged
t3
[1, 2, 3, 4]
This difference is important to write functions to modify lists.
(being them passed by reference, only)
This function does not delete the head of a list:
def bad_delete_head(t):
t = t[1:] # WRONG!
- the slice operator creates a new list
- the assignment makes
trefer to it - that doesn’t affect the caller
t4 = [1, 2, 3]
bad_delete_head(t4)
t4
[1, 2, 3]
An alternative is to write a function that creates and returns a new list
def tail(t):
return t[1:]
leaving the original list unmodified:
letters = ['a', 'b', 'c']
rest = tail(letters)
rest
['b', 'c']
Debugging¶
mutable objects (such as lists) can bring a lot of debugging.
Read the documentation carefully and then test in interactive mode.
Here below, some common pitfalls.
- Most list methods modify the argument and return
None.
The opposite of the string methods, which return a new string and leave the original alone.
If used to write code like this:
word = word.strip()
this is likely to fail (it returns None):
t = t.sort() # WRONG!
- Pick an idiom and stick with it.
Too many ways to do things (to remove/add elements in a list: pop, remove, del, append, extend).
Assuming that t is a list and x is a list element
these are correct:
t.append(x)
t = t + [x]
t += [x]
these are wrong:
t.append([x]) # WRONG!
t = t.append(x) # WRONG!
t + [x] # WRONG!
t = t + x # WRONG!
All, but the last one (causing a runtime error) are legal, but they do the wrong thing.
- Make copies to avoid aliasing.
Using methods that modify arguments, to keep the original list as well.
t1 = [3, 1, 2]
t2 = t1[:]
t2.sort()
t1
[3, 1, 2]
t2
[1, 2, 3]
or use the built-in function sorted:
- returns a new, sorted list
- leaves the original alone
t2 = sorted(t1)
t1
[3, 1, 2]
t2
[1, 2, 3]